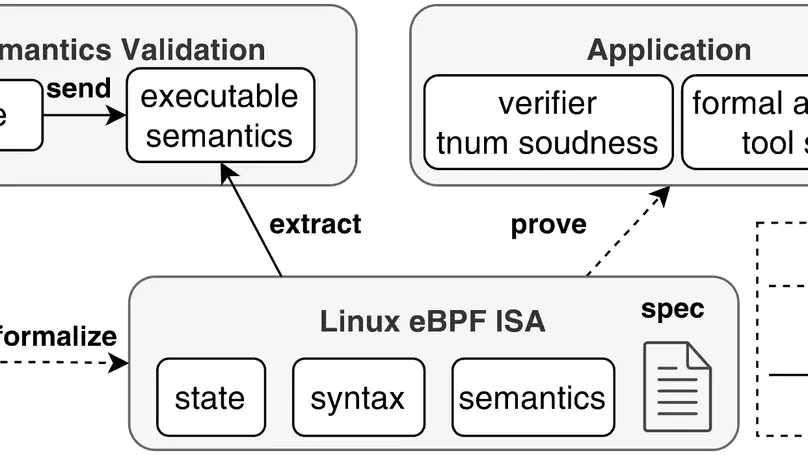
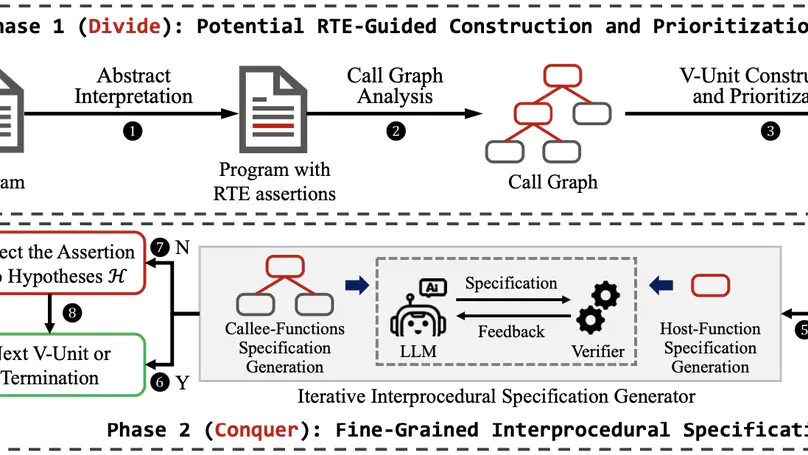
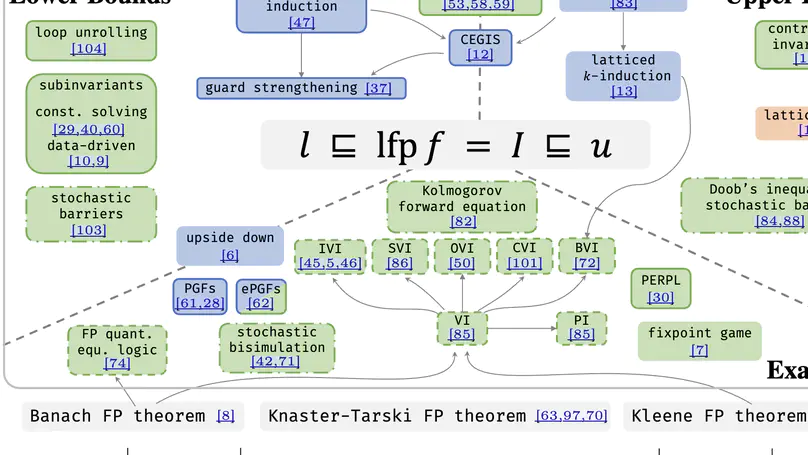
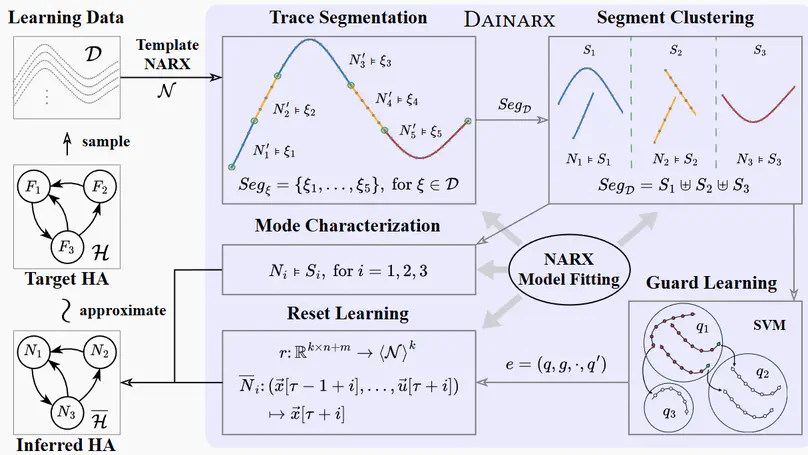
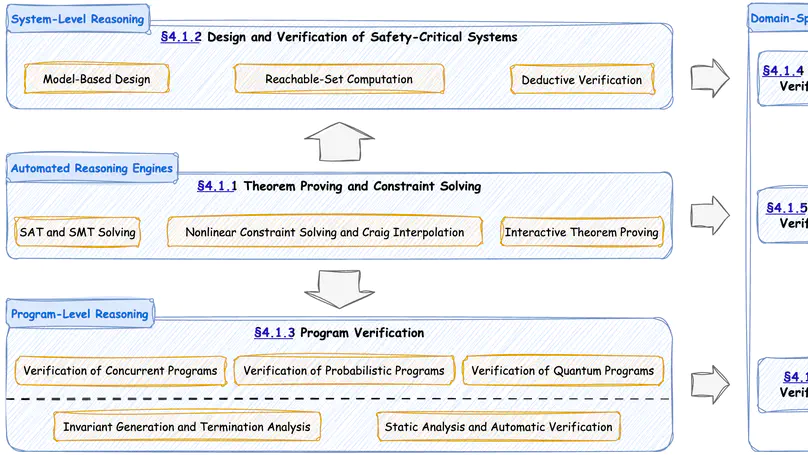
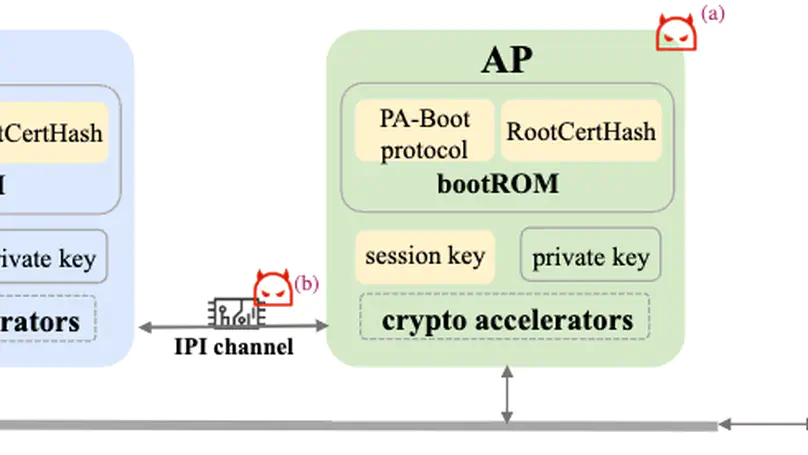
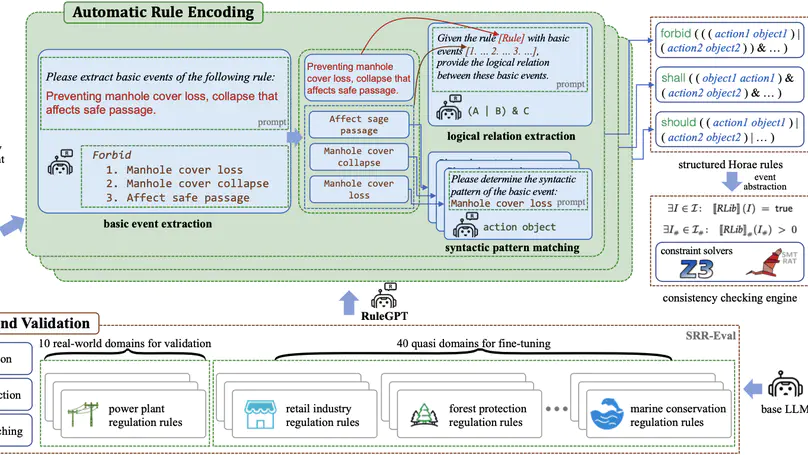
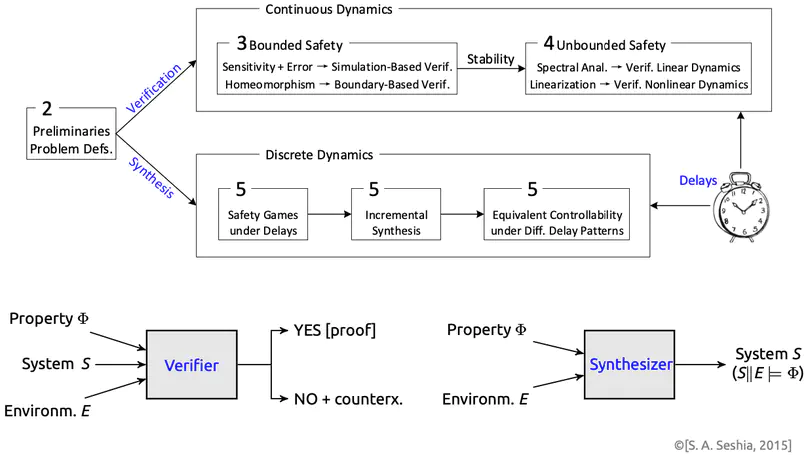
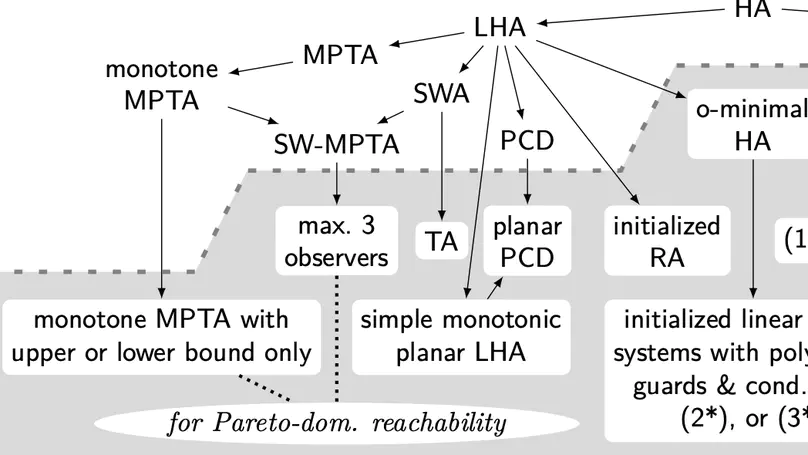
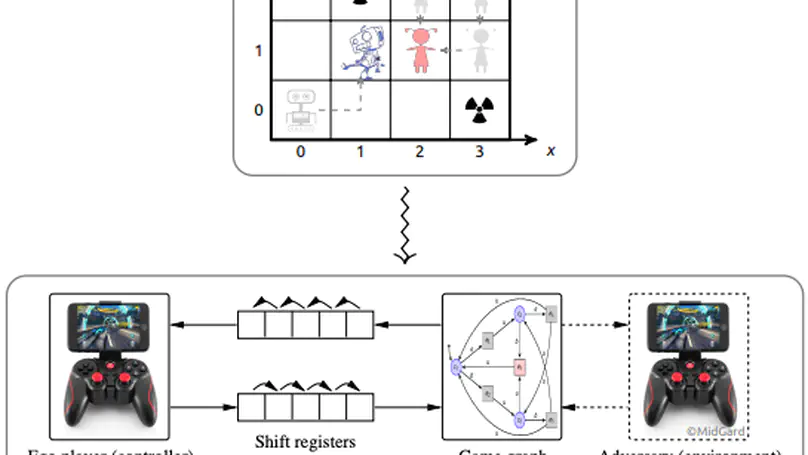
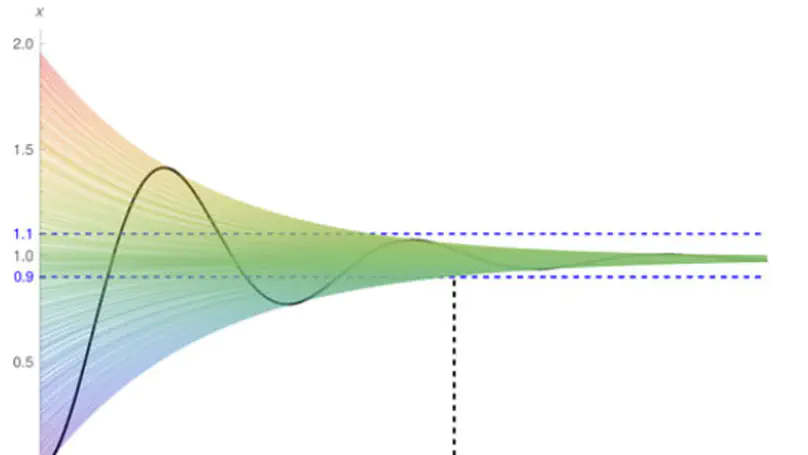
Publications
Visual latent reasoning lets a multimodal large language model (MLLM) create intermediate visual evidence as continuous tokens, avoiding external tools or image generators. However, existing methods usually follow an output-as-input latent paradigm and yield unstable gains. We identify evidence for a feature-space mismatch that can contribute to this instability: dominant visual-latent models build on pre-norm MLLMs and reuse decoder hidden states as predicted latent inputs, even though these states occupy a substantially different norm regime from the input embeddings the model was trained to consume (Xie et al., 2025; Li et al., 2026; Team et al., 2026). This mismatch can make direct latent feedback unreliable. Motivated by this diagnosis, we propose GAP, a Granular Alignment Paradigm for visual latent modeling. GAP aligns visual latent reasoning at three levels: feature-level alignment maps decoder outputs into input-compatible visual latents through a lightweight PCA-aligned latent head; context-level alignment grounds latent targets with inspectable auxiliary visual supervision; and capacity-guided alignment assigns latent supervision selectively to examples where the base MLLM struggles. On Qwen2.5-VL 7B, the resulting model achieves the best mean aggregate perception and reasoning performance among our supervised variants. Inference-time intervention probing further suggests that generated latents provide task-relevant visual signal beyond merely adding token slots.
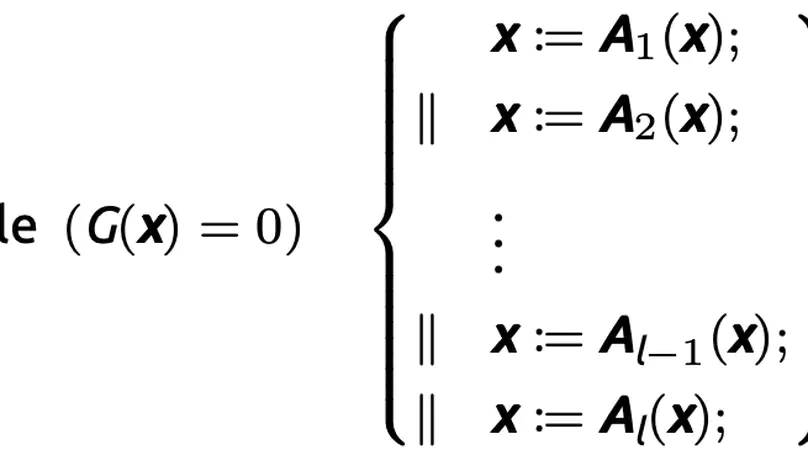

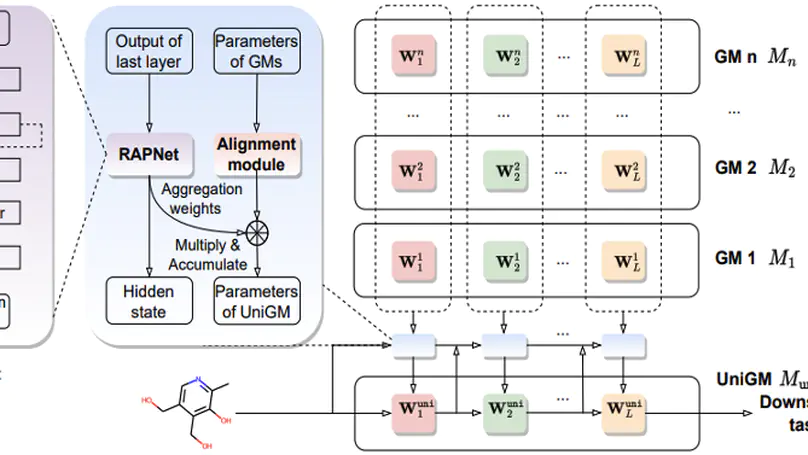
Recent years have witnessed remarkable advances in graph representation learning using Graph Neural Networks (GNNs). To fully exploit the unlabeled graphs, researchers pre-train GNNs on large-scale graph databases and then fine-tune these pre-trained Graph Models (GMs) for better performance in downstream tasks. Because different GMs are developed with diverse pre-training tasks or datasets, they can be complementary to each other for a more complete knowledge base. Naturally, a compelling question is emerging: How can we exploit the diverse knowledge captured by different GMs simultaneously in downstream tasks? In this paper, we make one of the first attempts to exploit multiple GMs to advance the performance in the downstream tasks. More specifically, for homogeneous GMs that share the same model architecture but are obtained with different pre-training tasks or datasets, we align each layer of these GMs and then aggregate them adaptively on a per-sample basis with a tailored Recurrent Aggregation Policy Network (RAPNet). For heterogeneous GMs with different model architectures, we design an alignment module to align the output of diverse GMs and a meta-learner to decide the importance of each GM conditioned on each sample automatically before aggregating the GMs. Extensive experiments on various downstream tasks from 3 domains reveal our dominance over each single GM. Additionally, our methods (UniGM) can achieve better performance with moderate computational overhead compared to alternative approaches including ensemble and model fusion. Also, we verify that our methods are not limited to graph data but could be flexibly applied to image and text data. The code can be seen in the anonymous link: https://anonymous.4open.science/r/UniGM-DA65.



{kind=link}
{kind=link}
{kind=link}
{kind=link}